 Back
Back
Taking on the “Haters”: Pentesting User Session Vulnerabilities
The Necessity of the Validation and Sanitation of URLs for Client-Side Work.
This post discusses the necessity of pentesting user session vulnerabilities – but how difficult it can be to get around individuals whose job it is to stop pentesters in their tracks.
As an application pentester, my life is relatively free of conflict. I lack the on-court physical conflict of a professional athlete battling her hated rivals, taunting them on various social media accounts, keeping up her stats, negotiating ever larger contracts with the team owners, training vigilantly against the day her ACL fails her.
Similarly, I lack the dense internal conflict of a lawyer defending the Bonesaw Puzzle Murderer, weighing the heinous, bonesaw-based infractions of his client against the Right to Bonesaw that is ensconced deep in American jurisprudence.
In fact, my professional life has one principal conflict:
I wish to perform malicious actions in the context of user sessions, but the Haters will not let me.
When I talk about The Haters here, there are a few different roles this term can include:
- Engineering teams who are wisely safeguarding their users’ financial data,
- third-party library developers who did not wake up with the intention of providing me with a SQLi swiss army knife,
- or sometimes, WAF designers who take a dim view of products named ”
OR 1=1 UNION SELECT PASSWORD,NULL,NULL;--oralert(‘xss’)</script>.
In the greater struggle for more secure software and more robust defenses, these individuals are both my cohorts and allies, but when I am testing, they are Haters, and they must be overcome.
During an idle few hours, I decided to see if I could find any vulnerabilities in a product that had popped up in our company’s intranet recently. (That company’s response to the resulting vulnerability report was pretty cantankerous, so I’ve decided to distill the vulnerability down to a more streamlined, less-actionable, anonymous version.) A bit of searching through client-side code came up with the following:
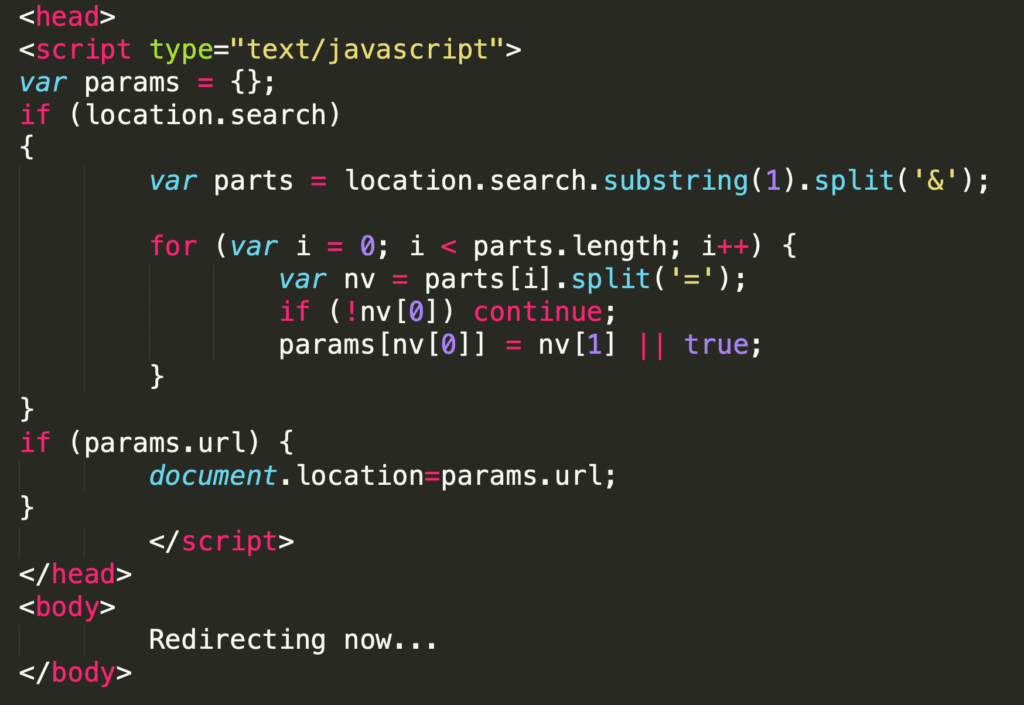
This code might look a bit thorny if you don’t spend a lot of time doing client-side work, but I have seen many variations of it before. I would not describe Javascript’s standard library as ‘robust’, and one of the many things it did not include for a long time is a simple way to get the parameters from URLs.
Basically, a URL like https://www.victim.com?param1=val1¶m2=val2 is converted to a Javascript dictionary quite often in client code, to something like the following:{
param1: "val1",
param2: "val2"
}
Seeing the document’s search string (user input!) transformed and used as the value of the document’s location caused my two remaining neurons to fire in harmony. At first glance, you may look and say “An open redirect vulnerability! Delightful!”. A more discerning reader might know that assignments to the URL that begin with javascript: cause execution of the subsequent Javascript in the current DOM context…a classic DOM XSS vulnerability. Circa 2008 these ‘bookmarkets’ were occasionally used to make a given page’s DIV elements rotate and blink to the delight and merriment of the end user; today they are almost exclusively used to exfiltrate PII from unsuspecting end users. I tried the classic way of verifying these: by trying to open the following URL:
https://www.victim.com?url=javascript:alert(1)
However, the fun was seemingly over at this point, as any URL that didn’t start with “/” or “https” was immediately killed by a server-side redirect to a 500 error. The Haters strike again! I couldn’t fault them for their intelligent use of whitelisting, or their correct checking of the start of the URL rather than its contents. (Often when these types of domain checks take place for runtime-defined redirects, I see code that looks like parameter.indexOf("victim.com") != -1 , rather than the correct parameter.toLowerCase().endsWith("victim.com") ). Whether it was custom logic or a particularly canny WAF, I was stuck.
Revisiting the above code, a thought occurred to me. The following code is great when the URL is well formed:

But what happens if someone is attempting to do…HTTP crimes to it? For example, in the case where the same URL parameter has been sent twice:
https://www.victim.com?param1=val1¶m2=val2¶m1=Newvalue
The above code will helpfully loop through the URL, assigning val1 to the key param1, val2 to param2, then…. overwriting the value of param1 with Newvalue! This is perfect! I thought to myself. I’m in the morass of HTTP implementation defined behavior!
In other words…the client behavior is visible, but what does the server actually do with this strange URL string? This is indeed an implementation-defined behavior, and there doesn’t seem to be a clear way to handle it. Most implementations simply take the first parameter, a very sparse few take the last, and some, like Node.JS’s Express, perform the extremely Big Brain™ technique of coercing the parameters into an array. (I wonder if this strange behavior has ever been correctly handled by applications that are not expecting it. Something to keep an eye out for if you are trying to fingerprint an app via user errors.)
Consistent, albeit strange handling of this vulnerability would not be a problem. However, different implementation-defined semantics in different parts of the application can cause problems here. The frontend JS’s handling and the backend’s parsing were different:
- The backend looks at the first parameter here, decides that it is a safe value, and then subsequently returns the normal page, whereas the frontend looks at the last parameter, executing it as script!
Hence, the attack in practice looks something like:
https://www.victim.com?url=https%3A%2F%2Fwww%2Evictim%2Ecom&url=javascript:alert(1)
Success! The backend WAF didn’t notice the second parameter, which the frontend happily executed. Not only that, but once I found this trick, it seemed to pop up everywhere. As mentioned before, using the last parameter as the ‘canonical’ instance is quite rare in backend appliances (for good reason in my opinion), but many older implementations of this algorithm use this technique. Until recently, the top answer on Stack Overflow provided a similar implementation as well. (I should mention here that the ‘canonical’ way to parse these URLs since 2016 has been the URLSearchParams API, but sadly thanks to a lack of support on IE you will probably have to polyfill it anyway.)
What is the moral of this story? No matter what shiny new API you end up using to parse URLs, the validation and sanitization of these URLs before assigning them to document.location is still necessary. This type of vulnerability to me represents a growing theme in modern application exploitation: the implementation semantics of different parts of an increasingly complex stack introduce impedance mismatch, which in turn introduces surprising attack surface into the application where it seemed safe.
Defense in depth will always be a useful mitigation (for example, a properly configured CSP would have stopped me in my tracks) but never a complete one. (It’s hard for me to guess what type of defense in depth would have stopped Portswigger’s latest round of Request Smuggling attacks, unless you were an HTTP/2 hardliner from day one.)